LA TEORÍA DE CÓDIGOS EN AUXILIO DE LA BIOTECNOLOGÍA
Un estudio conjunto del CNR-IMM y de la Universidad de Bolonia pone en relevancia una sorprendente conexión entre los códigos circulares del ADN y la síntesis de proteínas. Estos resultados pueden contribuir a la optimización de secuencias genómicas en aplicaciones de Bioinformática y Biotecnología. El trabajo fue publicado en la prestigiosa revista Scientific Reports, del grupo Nature.
Por Rafael Ferragut
Los códigos circulares, en general, permiten leer secuencias de palabras concatenadas sin necesidad de recurrir a símbolos de inicio y fin de las mismas. Nuestro genoma recurre a códigos de tipo circular para minimizar errores de lectura de los genes cuando son traducidos a proteínas. Los códigos circulares permiten, efectivamente, en la secuencia de nucleótidos del DNA, la identificación del marco de lectura correcto, o sea, de los sitios en donde empieza y termina la secuencia particular que codifica para una dada proteína (ver el ejemplo en la figura del artículo).
Un grupo de investigadores del Instituto para la Microelectrónica y los Microsistemas del Consejo Nacional de Investigaciones italiano (CNR-IMM) y de los Departamentos de Ciencias Estadísticas y de Farmacia y Biotecnología de la Universidad de Bolonia (UNIBO), descubrió una conexión entre estos códigos circulares y la eficiencia en la síntesis de proteínas. Estos resultados, publicados recientemente en la revista Scientific Reports, son relevantes porque pueden conducir a la definición de nuevos instrumentos universales para la optimización de secuencias genómicas en aplicaciones Bioinformáticas y de Biotecnología.
“La presencia de códigos circulares en secuencias genómicas codificantes (la parte di mRNA que resulta efectivamente leída y traducida en proteínas) ha sido hipotetizada por primera vez en 1996 y se especula podrían ser el resultado evolutivo de códigos ancestrales” explica Simone Giannerini, Profesor del Departamento de Ciencias Estadísticas “Paolo Fortunati” de la Universidad de Bolonia y primer autor del artículo.
“Esta investigación, fruto de una colaboración de más de una década entre el CNR-IMM y la Universidad de Bolonia, permitió identificar por primera vez propiedades universales (independientes del organismo considerado) sugeridas por la teoría de grupos de simetría, la teoría matemática en la cual se basan los códigos circulares. Sorprendentemente, tales propiedades universales, hasta ahora desconocidas, están correlacionadas con la eficiencia de la síntesis de proteínas, que se determina mediante técnicas sofisticadas de biología molecular” declara Diego González del CNR-IMM, uno de los autores del articulo y miembro RCAI.
“Además, con este enfoque, se ponen en evidencia propiedades universales de las secuencias codificantes en conexión con las transformaciones químicas de las bases nitrogenadas que componen dichas secuencias: de esta manera, se pueden dilucidar algunos procesos clave del complejo mecanismo que regula la síntesis de proteínas” agrega Alberto Danielli, Profesor del Departamento de Farmacia y Biotecnología de la Universidad de Bolonia.
Finalmente, Greta Goracci, Profesora del Departamento de Ciencias Estadísticas de la Universidad de Bolonia, comenta que, por ejemplo, en el marco de la pandemia que estamos viviendo, “estos conocimientos, aplicados a Sars-CoV-2, pueden ayudar a comprender si el genoma viral posee una optimización de la información genética que pueda favorecer la síntesis proteica del virus en detrimento de aquella del huésped”.
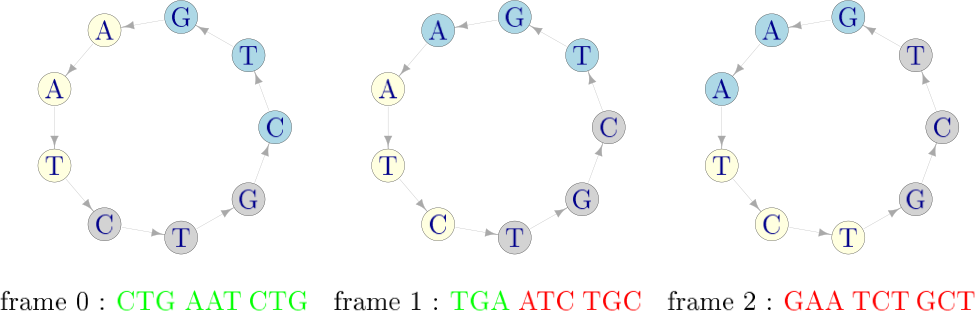
Representación esquemática de un código circular elemental. El código circular está compuesto por el conjunto de codones X = {CTG,AAT,TGA}. Con estos codones se construye una secuencia arbitraria, por ejemplo CTG AAT CTG;); si uno empieza a leer la secuencia a partir de la letra C (en celeste) y en sentido anti-horario, los grupos de tres letras generados (codones) pertenecen todos al código circular (evidenciados en verde en la línea inferior); si en cambio se comienza por la letra sucesiva (T), que corresponde a un frame-shift de 1 unidad, sólo el primer codón, TGA, es correcto; si se comienza por la siguiente letra (G), que corresponde a un frame-shift de 2 unidades, ninguno de los codones generados es correcto. Por lo tanto, el código circular permite de encontrar el marco de lectura correcto identificado como frame 0 en la figura, el único frame de lectura en el cual los tres codones generados pertenecen al código circular.
El trabajo original publicado en Scientific Reports puede encontrarse en el siguiente link.
En cambio, una nota de prensa conjunta CNR-Universidad de Bologna puede consultarse aquí.